Capítulo 9. Diagnosticar y medir el rendimiento
Una de las virtudes que más se suele publicitar de Julia es su velocidad de cálculo, incluso con enormes cantidades de datos. Pero la eficiencia de un programa depende de cómo esté construido. De hecho, un programa "mal escrito" (en el sentido de que no siga unas buenas prácticas de programación, aunque las operaciones sean correctas) puede resultar decepcionantemente lento.
Este capítulo y los siguientes están dedicados a herramientas que Julia pone a disposición de los usuarios para mejorar la eficiencia de sus programas. A la hora de optimizar un programa, es muy importante buscar primero dónde están los "cuellos de botella" (las partes del código que más lento lo hacen) y medir tanto su influencia como el efecto de las supuestas mejoras que se introducen. Por esta razón, comenzaremos por ver herramientas que sirven para hacer esos diagnósticos.
Ejemplo: pasos de las secuencias de Collatz
Para facilitar las explicaciones de este capítulo, vamos a usar como ejemplo el cálculo de secuencias de Collatz, series de números que comienzan con cualquier número natural, y que continúan según la siguiente regla, hasta llegar a 1:[1]
\[a_{i+1} = \begin{cases} \begin{array}{ll} a_i/2, & \textrm{si }a_i\textrm{ es par} \\ 3a_i+1, & \textrm{si }a_i\textrm{ es impar} \end{array} \end{cases}\]
Esta regla se puede expresar con una función como la que sigue:
siguiente_collatz(x) = iseven(x) ? x÷2 : 3x+1Pero para evitar problemas de desbordamiento (ya que las secuencias de Collatz podrían llegar a números excesivamente altos), podemos forzar que siempre se usen números de tipo BigInt:
siguiente_collatz(x::BigInt) = iseven(x) ? x÷2 : 3x+1
siguiente_collatz(x) = siguiente_collatz(BigInt(x))A continuación se define la función pasoscollatz, que calcula el número de pasos que tiene que darse en una secuencia de Collatz que comience en x hasta llegar a la unidad:
function pasoscollatz(x::Integer)
(x < 1) && throw(DomainError("solo se admiten números naturales a partir de uno"))
n = 0
s = BigInt(x)
while s > 1
s = siguiente_collatz(s)
n += 1
end
return n
endPara calcular ese valor de todas las secuencias de Collatz con inicios desde 1 hasta n, bastaría con escribir:
pasoscollatz.(1:1000)Pero es obvio que eso resulta un proceso poco ineficiente. Por la forma en la que se definen las secuencias de Collatz, se deduce que si conocemos el valor de pasoscollatz(y) para todos los valores de y < x, entonces para calcular pasoscollatz(x) solo haría falta contar los pasos de la secuencia desde x hasta que se alcanza el primer valor menor que x, y sumarles el resultado correspondiente a ese número menor.
Para implementar este otro algoritmo se define el siguiente método de pasoscollatz, que hace la cuenta de los pasos desde x hasta el primer número menor que x0, y también devuelve el valor de ese número:
function pasoscollatz(x::Integer, x0)
(x < 1) && throw(DomainError("solo se admiten números naturales a partir de uno"))
n = 0
s = BigInt(x)
while s ≥ x0
s == 1 && break
s = siguiente_collatz(s)
n += 1
end
return (n, s)
endY la función serie_pasoscollatz emplea ese método para calcular el número total de pasos de las secuencias que comienzan con valores desde 1 hasta n:
function serie_pasoscollatz(n)
pasos_total = zeros(Int, n)
for i=2:n
(pasos, inferior) = pasoscollatz(i, i)
pasos_total[i] = pasos + pasos_total[inferior]
end
return pasos_total
endMacros para medir consumos de tiempo y memoria
La herramienta más básica de Julia para medir la velocidad de una operación es un conjunto de macros que se pueden aplicar a cualquier expresión, para capturar el tiempo y la cantidad de memoria que se ha necesitado asignar al ejecutarla. La más elemental es @time, que ejecuta la expresión e imprime una información básica en pantalla. Con esto podríamos, por ejemplo, comparar la velocidad de las dos alternativas definidas antes para calcular las longitudes de las series de Collatz de 1 a n:
julia> @time pasoscollatz.(1:1000)
0.014103 seconds (279.48 k allocations: 4.888 MiB)
1000-element Vector{Int64}:
0
1
⋮
49
111
julia> @time serie_pasoscollatz(1000)
0.001451 seconds (27.12 k allocations: 495.336 KiB)
1000-element Vector{Int64}:
0
1
⋮
49
111De esta manera podemos comprobar rápidamente que la segunda versión es diez veces más eficiente que la primera. El valor exacto del tiempo y la memoria consumida en asignaciones depende del ordenador y también puede variar entre pruebas. En particular, la primera vez que se ejecuta una función se suele observar un mayor consumo de tiempo y memoria, porque parte de lo que se está midiendo es la compilación.
La macro @timev hace lo mismo que @time, pero muestra más detalles sobre el tiempo y memoria consumidas. Por otro lado la macro @elapsed no solo presenta el tiempo transcurrido en pantalla, sino que lo devuelve como resultado (en lugar del resultado de la operación evaluada).
Finalmente, la macro @timed devuelve las medidas de tiempo y memoria junto con el resultado de la operación y otras cosas en una tupla. Así, con x = @serie_pasoscollatz(1000) se obtendrían los siguientes valores:
x.valuecon el resultado de la expresión ejecutada.x.timecon el tiempo en segundos.x.bytescon el número de bytes de memoria asignados en la operación.x.gctimecon el tiempo consumido en garbage collection (gestión de la memoria).x.gcstatscon un objeto de tipoGC_Diffcon más detalles sobre la gestión de memoria.
Una alternativa muy popular a la macro @time es @btime del paquete BenchmarkTools. A nivel de uso son muy semejantes, con unas importantes salvedades:
@btimerepite la operación múltiples veces, hasta llegar a un objetivo de repeticiones o tiempo. Las medidas de tiempo y memoria mostradas son un promedio, que excluye los tiempos de compilación.@btimepermite interpolar los nombres de variables en la expresión para hacer más fiable el análisis. Por ejemplo, si el argumento deserie_pasoscollatz(x)estuviese guardado en la variablen, se podría escribir@btime serie_pasoscollatz($n).- La expresión pasada a
@btimeha de ser sencilla, idealmente una simple llamada a una función. Para asignar el resultado a una variable ha de escribirsey = @btime f(x), no@btime y = f(x).
El paquete BenchmarkTools también proporciona la macro @belapsed equivalente a @elapsed, así como @benchmark, que da estadísticas más detalladas de todas las repeticiones realizadas, como en el siguiente ejemplo:[2]
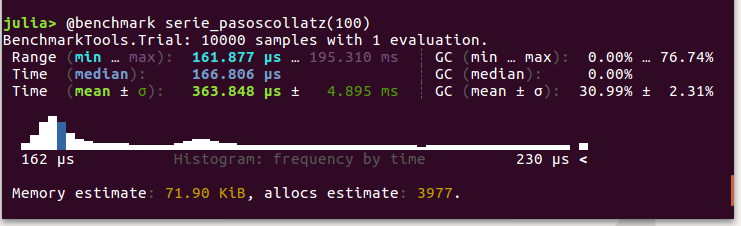
Profiling
Las macros anteriores son útiles para comparar distintas versiones de una función, o para hacer pruebas unitarias de las funciones que componen un programa. Pero los cuellos de botella a menudo aparecen en funciones que no presentan un gran coste en pruebas de ese tipo, y dependen de cómo, cuánto y dónde se emplean. Por otro lado, aunque con esas macros se puedan detectar funciones excesivamente costosas, queda el reto de averiguar en qué parte de sus operaciones radica el problema.
Para diagnósticar esas situaciones Julia dispone de la macro @profile y otras funciones en el módulo estándar Profile. La macro @profile se usa igual que @time, pero no muestra nada en pantalla, sino que guarda numerosos detalles sobre todas las operaciones relevantes que se ejecutan como parte de la expresión que sigue, incluyendo los tiempos que consumen y la memoria que asignan. El concepto de relevante aquí está determinado por unos umbrales que se fijan con la función Profile.init; uno de esos umbrales es el intervalo de tiempo entre cada "captura" de información, que por defecto está fijado en 1 ms. Esto implica que @profile detectará todas las funciones que cuestan más de 1 ms.
Cada vez que se usa la macro @profile, la información recogida hasta el momento se amplía con la de la expresión ejecutada, a no ser que se ejecute Profile.clear() para "limpiar el buffer". Hay distintas formas de ver la información acumulada. La más básica es la función Profile.print, que la muestra en forma de texto. Pero esa información es tan copiosa que no resulta una forma práctica de examinarla.
Lo más habitual es usar los llamados flame graphs, que muestran de forma visual el tiempo consumido por cada operación y las "suboperaciones" que las componen, de forma recursiva, hasta llegar el límite de resolución temporal que se haya usado en el registro de información. Cada operación se representa con una barra horizontal, cuya longitud es proporcional al tiempo que consume; una secuencia de operaciones se representa como una sucesión horizontal de barras, y las operaciones anidadas en otras se representan apilando las barras verticalmente. Esa disposición aporta a los gráficos una forma característica, que se puede comparar con un relieve montañoso, o con el perfil de una llama cuando se colorea con tonos rojos y amarillos —de ahí el nombre que reciben—.
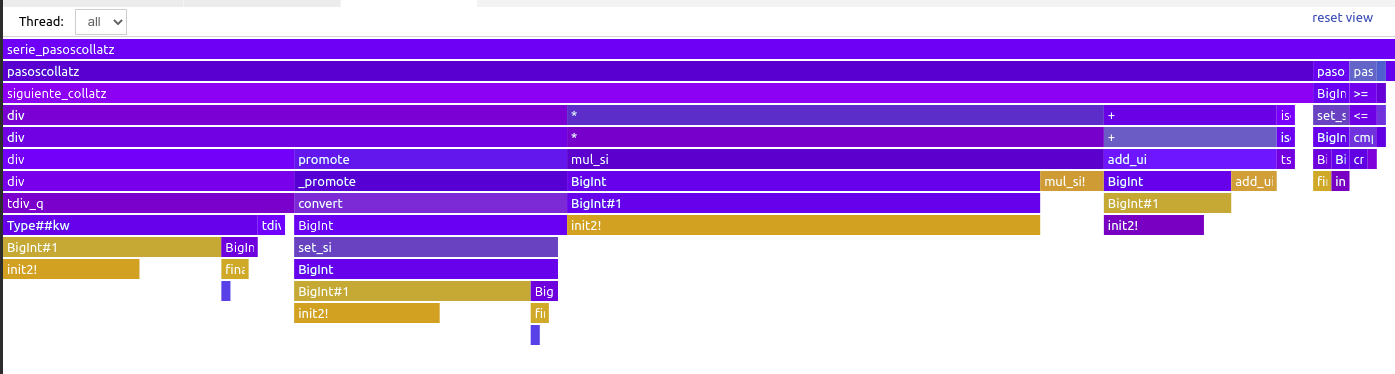
Hay diversos paquetes y otras herramientas para crear y visualizar flame graphs a partir de esos registros. La siguiente figura muestra el gráfico interactivo que resulta de monitorizar la función serie_pasoscollatz, tal como se ve en VS Code con su extensión para visualizar flame graphs.
Con esa extensión, VS Code no requiere cargar explícitamente el módulo Profile ni ningún otro paquete de Julia. Basta con escribir en el REPL:
@profview serie_pasoscollatz(100_000)Esa instrucción crea una tabla con la información de tiempos recogida, cuya visualización se puede alternar con la de un flame graph como el mostrado si se dispone de la extensión adecuada. (Si no está disponible, al intentar cambiar de vista aparece una sugerencia para instalarla.)
En este gráfico el eje vertical está invertido respecto al sentido que usan otros visualizadores: las operaciones anidadas se muestran debajo de las que las contienen, en lugar de arriba. Las primeras barras del flame graph completo (las que se muestran en la parte superior) suelen incluir información de operaciones que tienen poco interés para nuestro propósito, pues tienen que ver con el entorno en el que se ejecuta y se monitoriza la expresión a evaluar. En nuestro caso, la parte interesante es la que contiene nuestra función principal: serie_pasoscollatz, que es la que se muestra en la imagen. (Se puede llegar a esa vista de detalle pulsando con el ratón sobre la barra que contiene esa función.)
Naturalmente, serie_pasoscollatz y pasoscollatz en el siguiente nivel ocupan casi todo el rango horizontal de tiempos. También se puede ver que la mayor parte del tiempo dentro de pasoscollatz lo ocupa la función siguiente_collatz, aunque también hay un consumo de tiempo significativo que se invierte en operaciones de comparación, y en el constructor BigInt. Y dentro de siguiente_collatz, encontramos de forma más o menos equitativa la división entera (la función div) y otras operaciones aritméticas. A niveles inferiores hay muchos pequeños bloques de operaciones con el tipo BigInt. (En el pantallazo mostrado los nombres de funciones están cortados, pero en VS Code se puede hacer zoom y desplazarse para ver los detalles del gráfico.)
Ejemplo: aplicación de mejoras
No siempre es fácil interpretar los detalles de resultados como los mostrados anteriormente. Una primera observación del flame graph es que div (usada cuando el número de la secuencia es par) parece ocupar tanto o más tiempo que las operaciones de multiplicación y suma empleadas con los impares. Quien conozca la aritmética binaria con números enteros, puede caer rápidamente en la cuenta de que dividir por 2 es equivalente a desplazar los bits del número una posición, lo cual es más eficiente en el caso de BigInt:
julia> using BenchmarkTools
┌ Warning: The active manifest file is an older format with no julia version entry. Dependencies may have been resolved with a different julia version.
└ @ ~/Documentos/Helios/programacion/guia-julialang/Manifest.toml:0
Precompiling BenchmarkTools
[91m ✗ [39m[90mSparseArrays[39m
[91m ✗ [39m[90mStatistics[39m
Info Given BenchmarkTools was explicitly requested, output will be shown live [0K
[0K[91m[1mERROR: [22m[39mLoadError: ArgumentError: Package SparseArrays does not have SuiteSparse_jll in its dependencies:
[0K- You may have a partially installed environment. Try `Pkg.instantiate()`
[0K to ensure all packages in the environment are installed.
[0K- Or, if you have SparseArrays checked out for development and have
[0K added SuiteSparse_jll as a dependency but haven't updated your primary
[0K environment's manifest file, try `Pkg.resolve()`.
[0K- Otherwise you may need to report an issue with SparseArrays
[0KStacktrace:
[0K [1] [0m[1mmacro expansion[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1770[24m[39m[90m [inlined][39m
[0K [2] [0m[1mmacro expansion[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mlock.jl:267[24m[39m[90m [inlined][39m
[0K [3] [0m[1m__require[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1747[24m[39m
[0K [4] [0m[1m#invoke_in_world#3[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[0K [5] [0m[1minvoke_in_world[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[0K [6] [0m[1mrequire[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1740[24m[39m
[0K [7] [0m[1minclude[22m[0m[1m([22m[90mmod[39m::[0mModule, [90m_path[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m
[0K [8] [0m[1minclude[22m[0m[1m([22m[90mx[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [35mSparseArrays[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/[39m[90m[4mSparseArrays.jl:6[24m[39m
[0K [9] top-level scope
[0K[90m @[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/[39m[90m[4mSparseArrays.jl:77[24m[39m
[0K [10] [0m[1minclude[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m[90m [inlined][39m
[0K [11] [0m[1minclude_package_for_output[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90minput[39m::[0mString, [90mdepot_path[39m::[0mVector[90m{String}[39m, [90mdl_load_path[39m::[0mVector[90m{String}[39m, [90mload_path[39m::[0mVector[90m{String}[39m, [90mconcrete_deps[39m::[0mVector[90m{Pair{Base.PkgId, UInt128}}[39m, [90msource[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2216[24m[39m
[0K [12] top-level scope
[0K[90m @[39m [90m[4mstdin:3[24m[39m
[0Kin expression starting at /home/meliana/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/solvers/LibSuiteSparse.jl:1
[0Kin expression starting at /home/meliana/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/SparseArrays.jl:3
[0Kin expression starting at stdin:3
[0K[91m[1mERROR: [22m[39mLoadError: Failed to precompile SparseArrays [2f01184e-e22b-5df5-ae63-d93ebab69eaf] to "/home/meliana/.julia/compiled/v1.10/SparseArrays/jl_wJosPb".
[0KStacktrace:
[0K [1] [0m[1merror[22m[0m[1m([22m[90ms[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4merror.jl:35[24m[39m
[0K [2] [0m[1mcompilecache[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90mpath[39m::[0mString, [90minternal_stderr[39m::[0mIO, [90minternal_stdout[39m::[0mIO, [90mkeep_loaded_modules[39m::[0mBool[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2462[24m[39m
[0K [3] [0m[1mcompilecache[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2334[24m[39m[90m [inlined][39m
[0K [4] [0m[1m(::Base.var"#968#969"{Base.PkgId})[22m[0m[1m([22m[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1968[24m[39m
[0K [5] [0m[1mmkpidlock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mat[39m::[0mString, [90mpid[39m::[0mInt32; [90mkwopts[39m::[0m@Kwargs[90m{stale_age::Int64, wait::Bool}[39m[0m[1m)[22m
[0K[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:93[24m[39m
[0K [6] [0m[1m#mkpidlock#6[22m
[0K[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:88[24m[39m[90m [inlined][39m
[0K [7] [0m[1mtrymkpidlock[22m[0m[1m([22m::[0mFunction, ::[0mVararg[90m{Any}[39m; [90mkwargs[39m::[0m@Kwargs[90m{stale_age::Int64}[39m[0m[1m)[22m
[0K[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:111[24m[39m
[0K [8] [0m[1m#invokelatest#2[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:889[24m[39m[90m [inlined][39m
[0K [9] [0m[1minvokelatest[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:884[24m[39m[90m [inlined][39m
[0K [10] [0m[1mmaybe_cachefile_lock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mpkg[39m::[0mBase.PkgId, [90msrcpath[39m::[0mString; [90mstale_age[39m::[0mInt64[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2977[24m[39m
[0K [11] [0m[1mmaybe_cachefile_lock[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2974[24m[39m[90m [inlined][39m
[0K [12] [0m[1m_require[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1964[24m[39m
[0K [13] [0m[1m__require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1806[24m[39m
[0K [14] [0m[1m#invoke_in_world#3[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[0K [15] [0m[1minvoke_in_world[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[0K [16] [0m[1m_require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1797[24m[39m
[0K [17] [0m[1mmacro expansion[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1784[24m[39m[90m [inlined][39m
[0K [18] [0m[1mmacro expansion[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mlock.jl:267[24m[39m[90m [inlined][39m
[0K [19] [0m[1m__require[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1747[24m[39m
[0K [20] [0m[1m#invoke_in_world#3[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[0K [21] [0m[1minvoke_in_world[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[0K [22] [0m[1mrequire[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1740[24m[39m
[0K [23] [0m[1minclude[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m[90m [inlined][39m
[0K [24] [0m[1minclude_package_for_output[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90minput[39m::[0mString, [90mdepot_path[39m::[0mVector[90m{String}[39m, [90mdl_load_path[39m::[0mVector[90m{String}[39m, [90mload_path[39m::[0mVector[90m{String}[39m, [90mconcrete_deps[39m::[0mVector[90m{Pair{Base.PkgId, UInt128}}[39m, [90msource[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2216[24m[39m
[0K [25] top-level scope
[0K[90m @[39m [90m[4mstdin:3[24m[39m
[0Kin expression starting at /home/meliana/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/Statistics/src/Statistics.jl:3
[0Kin expression starting at stdin:3
[0K[91m[1mERROR: [22m[39mLoadError: Failed to precompile Statistics [10745b16-79ce-11e8-11f9-7d13ad32a3b2] to "/home/meliana/.julia/compiled/v1.10/Statistics/jl_HH50LE".
[0KStacktrace:
[0K [1] [0m[1merror[22m[0m[1m([22m[90ms[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4merror.jl:35[24m[39m
[0K [2] [0m[1mcompilecache[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90mpath[39m::[0mString, [90minternal_stderr[39m::[0mIO, [90minternal_stdout[39m::[0mIO, [90mkeep_loaded_modules[39m::[0mBool[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2462[24m[39m
[0K [3] [0m[1mcompilecache[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2334[24m[39m[90m [inlined][39m
[0K [4] [0m[1m(::Base.var"#968#969"{Base.PkgId})[22m[0m[1m([22m[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1968[24m[39m
[0K [5] [0m[1mmkpidlock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mat[39m::[0mString, [90mpid[39m::[0mInt32; [90mkwopts[39m::[0m@Kwargs[90m{stale_age::Int64, wait::Bool}[39m[0m[1m)[22m
[0K[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:93[24m[39m
[0K [6] [0m[1m#mkpidlock#6[22m
[0K[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:88[24m[39m[90m [inlined][39m
[0K [7] [0m[1mtrymkpidlock[22m[0m[1m([22m::[0mFunction, ::[0mVararg[90m{Any}[39m; [90mkwargs[39m::[0m@Kwargs[90m{stale_age::Int64}[39m[0m[1m)[22m
[0K[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:111[24m[39m
[0K [8] [0m[1m#invokelatest#2[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:889[24m[39m[90m [inlined][39m
[0K [9] [0m[1minvokelatest[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:884[24m[39m[90m [inlined][39m
[0K [10] [0m[1mmaybe_cachefile_lock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mpkg[39m::[0mBase.PkgId, [90msrcpath[39m::[0mString; [90mstale_age[39m::[0mInt64[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2977[24m[39m
[0K [11] [0m[1mmaybe_cachefile_lock[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2974[24m[39m[90m [inlined][39m
[0K [12] [0m[1m_require[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1964[24m[39m
[0K [13] [0m[1m__require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1806[24m[39m
[0K [14] [0m[1m#invoke_in_world#3[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[0K [15] [0m[1minvoke_in_world[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[0K [16] [0m[1m_require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1797[24m[39m
[0K [17] [0m[1mmacro expansion[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1784[24m[39m[90m [inlined][39m
[0K [18] [0m[1mmacro expansion[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mlock.jl:267[24m[39m[90m [inlined][39m
[0K [19] [0m[1m__require[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1747[24m[39m
[0K [20] [0m[1m#invoke_in_world#3[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[0K [21] [0m[1minvoke_in_world[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[0K [22] [0m[1mrequire[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1740[24m[39m
[0K [23] [0m[1minclude[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m[90m [inlined][39m
[0K [24] [0m[1minclude_package_for_output[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90minput[39m::[0mString, [90mdepot_path[39m::[0mVector[90m{String}[39m, [90mdl_load_path[39m::[0mVector[90m{String}[39m, [90mload_path[39m::[0mVector[90m{String}[39m, [90mconcrete_deps[39m::[0mVector[90m{Pair{Base.PkgId, UInt128}}[39m, [90msource[39m::[0mNothing[0m[1m)[22m
[0K[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2216[24m[39m
[0K [25] top-level scope
[0K[90m @[39m [90m[4mstdin:3[24m[39m
[0Kin expression starting at /home/meliana/.julia/packages/BenchmarkTools/O3UL3/src/BenchmarkTools.jl:1
[0Kin expression starting at stdin:3
[91m ✗ [39mBenchmarkTools
0 dependencies successfully precompiled in 28 seconds. 2 already precompiled.
ERROR: The following 1 direct dependency failed to precompile:
BenchmarkTools [6e4b80f9-dd63-53aa-95a3-0cdb28fa8baf]
Failed to precompile BenchmarkTools [6e4b80f9-dd63-53aa-95a3-0cdb28fa8baf] to "/home/meliana/.julia/compiled/v1.10/BenchmarkTools/jl_aylBkG".
[91m[1mERROR: [22m[39mLoadError: ArgumentError: Package SparseArrays does not have SuiteSparse_jll in its dependencies:
- You may have a partially installed environment. Try `Pkg.instantiate()`
to ensure all packages in the environment are installed.
- Or, if you have SparseArrays checked out for development and have
added SuiteSparse_jll as a dependency but haven't updated your primary
environment's manifest file, try `Pkg.resolve()`.
- Otherwise you may need to report an issue with SparseArrays
Stacktrace:
[1] [0m[1mmacro expansion[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1770[24m[39m[90m [inlined][39m
[2] [0m[1mmacro expansion[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mlock.jl:267[24m[39m[90m [inlined][39m
[3] [0m[1m__require[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1747[24m[39m
[4] [0m[1m#invoke_in_world#3[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[5] [0m[1minvoke_in_world[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[6] [0m[1mrequire[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1740[24m[39m
[7] [0m[1minclude[22m[0m[1m([22m[90mmod[39m::[0mModule, [90m_path[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m
[8] [0m[1minclude[22m[0m[1m([22m[90mx[39m::[0mString[0m[1m)[22m
[90m @[39m [35mSparseArrays[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/[39m[90m[4mSparseArrays.jl:6[24m[39m
[9] top-level scope
[90m @[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/[39m[90m[4mSparseArrays.jl:77[24m[39m
[10] [0m[1minclude[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m[90m [inlined][39m
[11] [0m[1minclude_package_for_output[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90minput[39m::[0mString, [90mdepot_path[39m::[0mVector[90m{String}[39m, [90mdl_load_path[39m::[0mVector[90m{String}[39m, [90mload_path[39m::[0mVector[90m{String}[39m, [90mconcrete_deps[39m::[0mVector[90m{Pair{Base.PkgId, UInt128}}[39m, [90msource[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2216[24m[39m
[12] top-level scope
[90m @[39m [90m[4mstdin:3[24m[39m
in expression starting at /home/meliana/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/solvers/LibSuiteSparse.jl:1
in expression starting at /home/meliana/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/SparseArrays/src/SparseArrays.jl:3
in expression starting at stdin:3
[91m[1mERROR: [22m[39mLoadError: Failed to precompile SparseArrays [2f01184e-e22b-5df5-ae63-d93ebab69eaf] to "/home/meliana/.julia/compiled/v1.10/SparseArrays/jl_wJosPb".
Stacktrace:
[1] [0m[1merror[22m[0m[1m([22m[90ms[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4merror.jl:35[24m[39m
[2] [0m[1mcompilecache[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90mpath[39m::[0mString, [90minternal_stderr[39m::[0mIO, [90minternal_stdout[39m::[0mIO, [90mkeep_loaded_modules[39m::[0mBool[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2462[24m[39m
[3] [0m[1mcompilecache[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2334[24m[39m[90m [inlined][39m
[4] [0m[1m(::Base.var"#968#969"{Base.PkgId})[22m[0m[1m([22m[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1968[24m[39m
[5] [0m[1mmkpidlock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mat[39m::[0mString, [90mpid[39m::[0mInt32; [90mkwopts[39m::[0m@Kwargs[90m{stale_age::Int64, wait::Bool}[39m[0m[1m)[22m
[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:93[24m[39m
[6] [0m[1m#mkpidlock#6[22m
[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:88[24m[39m[90m [inlined][39m
[7] [0m[1mtrymkpidlock[22m[0m[1m([22m::[0mFunction, ::[0mVararg[90m{Any}[39m; [90mkwargs[39m::[0m@Kwargs[90m{stale_age::Int64}[39m[0m[1m)[22m
[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:111[24m[39m
[8] [0m[1m#invokelatest#2[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:889[24m[39m[90m [inlined][39m
[9] [0m[1minvokelatest[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:884[24m[39m[90m [inlined][39m
[10] [0m[1mmaybe_cachefile_lock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mpkg[39m::[0mBase.PkgId, [90msrcpath[39m::[0mString; [90mstale_age[39m::[0mInt64[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2977[24m[39m
[11] [0m[1mmaybe_cachefile_lock[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2974[24m[39m[90m [inlined][39m
[12] [0m[1m_require[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1964[24m[39m
[13] [0m[1m__require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1806[24m[39m
[14] [0m[1m#invoke_in_world#3[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[15] [0m[1minvoke_in_world[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[16] [0m[1m_require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1797[24m[39m
[17] [0m[1mmacro expansion[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1784[24m[39m[90m [inlined][39m
[18] [0m[1mmacro expansion[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mlock.jl:267[24m[39m[90m [inlined][39m
[19] [0m[1m__require[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1747[24m[39m
[20] [0m[1m#invoke_in_world#3[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[21] [0m[1minvoke_in_world[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[22] [0m[1mrequire[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1740[24m[39m
[23] [0m[1minclude[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m[90m [inlined][39m
[24] [0m[1minclude_package_for_output[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90minput[39m::[0mString, [90mdepot_path[39m::[0mVector[90m{String}[39m, [90mdl_load_path[39m::[0mVector[90m{String}[39m, [90mload_path[39m::[0mVector[90m{String}[39m, [90mconcrete_deps[39m::[0mVector[90m{Pair{Base.PkgId, UInt128}}[39m, [90msource[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2216[24m[39m
[25] top-level scope
[90m @[39m [90m[4mstdin:3[24m[39m
in expression starting at /home/meliana/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/Statistics/src/Statistics.jl:3
in expression starting at stdin:3
[91m[1mERROR: [22m[39mLoadError: Failed to precompile Statistics [10745b16-79ce-11e8-11f9-7d13ad32a3b2] to "/home/meliana/.julia/compiled/v1.10/Statistics/jl_HH50LE".
Stacktrace:
[1] [0m[1merror[22m[0m[1m([22m[90ms[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4merror.jl:35[24m[39m
[2] [0m[1mcompilecache[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90mpath[39m::[0mString, [90minternal_stderr[39m::[0mIO, [90minternal_stdout[39m::[0mIO, [90mkeep_loaded_modules[39m::[0mBool[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2462[24m[39m
[3] [0m[1mcompilecache[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2334[24m[39m[90m [inlined][39m
[4] [0m[1m(::Base.var"#968#969"{Base.PkgId})[22m[0m[1m([22m[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1968[24m[39m
[5] [0m[1mmkpidlock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mat[39m::[0mString, [90mpid[39m::[0mInt32; [90mkwopts[39m::[0m@Kwargs[90m{stale_age::Int64, wait::Bool}[39m[0m[1m)[22m
[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:93[24m[39m
[6] [0m[1m#mkpidlock#6[22m
[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:88[24m[39m[90m [inlined][39m
[7] [0m[1mtrymkpidlock[22m[0m[1m([22m::[0mFunction, ::[0mVararg[90m{Any}[39m; [90mkwargs[39m::[0m@Kwargs[90m{stale_age::Int64}[39m[0m[1m)[22m
[90m @[39m [35mFileWatching.Pidfile[39m [90m~/.julia/juliaup/julia-1.10.0+0.x64.linux.gnu/share/julia/stdlib/v1.10/FileWatching/src/[39m[90m[4mpidfile.jl:111[24m[39m
[8] [0m[1m#invokelatest#2[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:889[24m[39m[90m [inlined][39m
[9] [0m[1minvokelatest[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:884[24m[39m[90m [inlined][39m
[10] [0m[1mmaybe_cachefile_lock[22m[0m[1m([22m[90mf[39m::[0mBase.var"#968#969"[90m{Base.PkgId}[39m, [90mpkg[39m::[0mBase.PkgId, [90msrcpath[39m::[0mString; [90mstale_age[39m::[0mInt64[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2977[24m[39m
[11] [0m[1mmaybe_cachefile_lock[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2974[24m[39m[90m [inlined][39m
[12] [0m[1m_require[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1964[24m[39m
[13] [0m[1m__require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1806[24m[39m
[14] [0m[1m#invoke_in_world#3[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[15] [0m[1minvoke_in_world[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[16] [0m[1m_require_prelocked[22m[0m[1m([22m[90muuidkey[39m::[0mBase.PkgId, [90menv[39m::[0mString[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1797[24m[39m
[17] [0m[1mmacro expansion[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1784[24m[39m[90m [inlined][39m
[18] [0m[1mmacro expansion[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mlock.jl:267[24m[39m[90m [inlined][39m
[19] [0m[1m__require[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1747[24m[39m
[20] [0m[1m#invoke_in_world#3[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:921[24m[39m[90m [inlined][39m
[21] [0m[1minvoke_in_world[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4messentials.jl:918[24m[39m[90m [inlined][39m
[22] [0m[1mrequire[22m[0m[1m([22m[90minto[39m::[0mModule, [90mmod[39m::[0mSymbol[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:1740[24m[39m
[23] [0m[1minclude[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mBase.jl:495[24m[39m[90m [inlined][39m
[24] [0m[1minclude_package_for_output[22m[0m[1m([22m[90mpkg[39m::[0mBase.PkgId, [90minput[39m::[0mString, [90mdepot_path[39m::[0mVector[90m{String}[39m, [90mdl_load_path[39m::[0mVector[90m{String}[39m, [90mload_path[39m::[0mVector[90m{String}[39m, [90mconcrete_deps[39m::[0mVector[90m{Pair{Base.PkgId, UInt128}}[39m, [90msource[39m::[0mNothing[0m[1m)[22m
[90m @[39m [90mBase[39m [90m./[39m[90m[4mloading.jl:2216[24m[39m
[25] top-level scope
[90m @[39m [90m[4mstdin:3[24m[39m
in expression starting at /home/meliana/.julia/packages/BenchmarkTools/O3UL3/src/BenchmarkTools.jl:1
in expression starting at stdin:
julia> mitad(x) = x ÷ 2 # operación con `div`
mitad (generic function with 1 method)
julia> mitadb(x) = x >>> 1 # operación binaria
mitadb (generic function with 1 method)
julia> x = big"6782"
6782
julia> @btime mitad($x)
ERROR: LoadError: UndefVarError: `@btime` not defined
in expression starting at none:1
julia> @btime mitadb($x)
ERROR: LoadError: UndefVarError: `@btime` not defined
in expression starting at none:1Así pues, una posible mejora sería cambiar la operación de división en la función siguiente_collatz. Por otro lado, también se puede considerar que el hecho de hacer operaciones con BigInt añade una carga significativa, y que podría aumentarse la eficiencia utilizando otros tipos de números enteros. El precio a pagar sería el riesgo de cometer errores, si en alguna secuencia se supera el límite de desbordamiento para ese tipo.
En la práctica, con la mayoría de ordenadores personales se pueden calcular las secuencias de Collatz usando tipos de enteros menos costosos sin superar su límite de desbordamiento, antes de que el tamaño del vector generado con serie_pasoscollatz sea inmanejable. Por lo tanto sería razonable modificar las funciones anteriores para evitar el retardo sistemático provocado por usar BigInt.
Juntando esas dos ideas, el método genérico de siguiente_collatz podría modificarse como sigue, para que devuelva un número del mismo tipo de entero introducido:
function siguiente_collatz(x::T) where T<:Integer
if iseven(x)
return x >>> 1
else
if x > typemax(T) ÷ 3
throw(DomainError("la secuencia excede del límite superior para $T"))
end
return T(3)*x + one(T)
end
endAsimismo, las otras dos funciones (pasoscollatz y serie_pasoscollatz), se podrían modificar del siguiente modo para que las secuencias contengan el tipo de entero que se introduce como argumento:
function pasoscollatz(x::Integer, x0)
(x < 1) && throw(DomainError("solo se admiten números naturales a partir de uno"))
n = 0
while x ≥ x0
x == 1 && break
x = siguiente_collatz(x)
n += 1
end
return (n, x)
end
function serie_pasoscollatz(n::T) where T<:Integer
pasos_total = zeros(Int, n)
for i=range(T(2), stop=n)
(pasos, inferior) = pasoscollatz(i, i)
pasos_total[i] = pasos + pasos_total[inferior]
end
return pasos_total
endCualquiera de las medidas de benchmarking expuestas anteriormente muestra que esta nueva versión de serie_pasoscollatz es cien veces más rápida que la basada en BigInt.
- 1No está matemáticamente probado que todas las secuencias de Collatz posibles acaben llegado a 1, pero es una conjetura verificada para los primeros trillones de números naturales. Puede verse una estupenda introducción a este problema en Veritasium, entre otros sitios.
- 2El resultado mostrado se corresponde con la versión 1.1 de BenchmarkTools.