Capítulo 10. Detección y depuración de errores
Los errores son inevitables a la hora de desarrollar un programa, hasta el punto que la estrategia más eficaz para prevenirlos no es tanto evitar que ocurran, sino intentar detectarlos y corregirlos rápidamente. En el último capítulo de esta guía vamos a ver algunas buenas prácticas y herramientas que facilitan esta tarea, tratando de evitar algunos pasos en falso y atolladeros comunes.
Tipos de errores
Comencemos por ver los tres tipos de errores más comunes con los que nos solemos encontrar en un programa.
Errores de código. Con este tipo de errores nos referimos a los fallos cometidos por confusiones en los nombres de funciones o variables, por escoger las operaciones que no tocan, definir de forma incorrecta bucles o condiciones, etc. En la mayoría de casos estos fallos provocan errores sistemáticos, interrupciones del programa o resultados inesperados en los primeros intentos de uso, lo que facilita su detección.
Errores ocasionales. Consisten en el típico bug que hace fallar misteriosamente un programa que parecía funcionar bien. A menudo son más difíciles de detectar, porque no siempre aparecen de forma sistemática. Suelen darse al usar datos que no cumplen alguna hipótesis implícita en el diseño del programa, que producen valores singulares, resultados fuera de rango, bucles infinitos, etc. A veces no dependen solo de los datos de entrada, sino también de las operaciones que se hayan hecho antes.
Errores por cambio de versión. El programa funcionaba perfectamente, pero después de una actualización del sistema o de los paquetes, deja de hacerlo. Es un tipo de error muy frustrante, pero afortunadamente fácil de detectar, y en el caso de Julia también es fácil de prevenir gracias al sistema de entornos por proyectos.
A continuación se comentan algunas prácticas de programación que ayudan a prevenir distintos tipos de errores, seguidas de algunas herramientas específicas de Julia que sirven de apoyo a dichas prácticas.
Buscar y usar paquetes
Cuando estás haciendo un programa para resolver un problema, vale la pena detenerse y buscar si hay alguien que ya haya resuelto antes el mismo o uno parecido. Es muy probable que al menos una parte del problema requiera herramientas que ya están desarrolladas, puestas a prueba y optimizadas en paquetes. En el capítulo anterior se encuentran algunas referencias para buscar paquetes de Julia, instalarlos y usarlos.
Usar paquetes de terceros tiene varias ventajas, entre las que se cuentan las siguientes:
- Ahorro de tiempo y esfuerzo de programación, que se puede invertir en las partes del problema más originales.
- A menudo los paquetes son el resultado de un trabajo colaborativo entre desarrolladores y usuarios, lo que reduce el riesgo de fallos.
- Si es un paquete suficientemente usado, los canales de comunicación de la "comunidad" de usuarios de Julia (foros de discusión, chats, etc.) pueden ser de ayuda para resolver el problema con el apoyo del paquete.
Naturalmente, el uso de paquetes también puede presentar algunas desventajas que vale la pena valorar. La carga de estos problemas varía mucho de un paquete a otro; hay algunos en los que es despreciable, y otros en los que es bastante importante:
- Para sacar partido a un paquete hay que aprender a emplearlo, lo cual puede ser más o menos difícil en función del diseño del paquete y de la documentación de que disponga.
- En ciertos casos el "peso" de un paquete es desproporcionado respecto a la parte del problema que se busca resolver, en términos de espacio que consume o dependencias que tiene que instalar (sobre todo si son herramientas del sistema operativo o programas externos a Julia, que pueden presentar problemas de instalación). En tales casos cabe considerar si las capacidades que proporciona el paquete podrían ser útiles en otros proyectos, o si existen otros paquetes más básicos para el problema en cuestión.
- Una vez instalados, la mayoría de paquetes se suelen cargan en cuestión de unos pocos segundos cuando se usan por primera vez en una sesión de trabajo, pero algunos pueden tardar más, incluso más de un minuto (dependiendo del paquete y del ordenador). Esta espera puede hacerse más larga después de alguna actualización.
Por otro lado, algunos inconvenientes en los que se podría pensar a la hora de utilizar paquetes de terceros están bien resueltos en el caso de Julia, y normalmente no hay que preocuparse de ellos:
- Los problemas de compatibilidad entre versiones de los paquetes, y de falta de reproducibilidad a causa de sus actualizaciones, se controlan de forma muy eficaz al trabajar por proyectos, como se ha indicado arriba.
- En cuanto a la explotación de programas que usen paquetes de terceros, la práctica habitual en la comunidad de desarrolladores de Julia es publicar los paquetes bajo la licencia MIT o semejante, lo que da libertad de usarlos y modificarlos, incluso para software propietario y cerrado.
Encapsular código en funciones pequeñas
Cuando se comienza a trabajar en un proyecto con datos que se han de procesar o analizar, lo primero que se hace normalmente es explorar los datos, ver algunos de muestra, representarlos en gráficos, etc. Esto suele hacerse en un entorno interactivo, que da mucha flexibilidad al usuario para crear nuevas variables, modificarlas de forma arbitraria, y hacer operaciones paso a paso, viendo lo que pasa después de cada operación antes de proceder a la siguiente.
Las funciones, por otro lado, están pensadas para un flujo de trabajo mucho más sistemático, con una secuencia de operaciones concreta aplicadas a un conjunto cerrado de variables, que se van generando y modificando conforme a un guión predefinido. Esto podría hacer pensar que no vale la pena crear funciones hasta que los algoritmos a emplear en el proyecto estén suficientemente claros, o al menos hasta que se hayan definido rutinas lo suficientemente largas y repetitivas como para que guardar el código de la función suponga un ahorro de trabajo significativo.
Sin embargo, en general es ventajoso empezar a encapsular el código en pequeñas funciones desde casi el principio. En Julia se recomienda definir funciones sencillas porque así es más fácil asegurar la estabilidad de tipos, lo que permite que se compilen de forma óptima y se ejecuten más rápido. Pero otra ventaja muy importante, que además es común a todos los lenguajes de programación, es que encapsular secuencias de operaciones en funciones hace que los pasos realizados durante el análisis, incluso en las primeras fases exploratorias, sean más repetibles y menos propensos a errores. Además, esto permite que el código sea más conciso, más modular y fácil de leer y entender posteriormente por el propio autor o por otros.
Las funciones sencillas también facilitan el uso de tests unitarios y las herramientas de debugging, que se comentan en secciones posteriores como estrategias para prevenir y arreglar errores en los programas.
Documentar el código
Aunque Julia se considere un lenguaje "de alto nivel", el código de un programa de Julia dista mucho del lenguaje natural, por lo que entender lo que hace no suele ser fácil, salvo por parte de la persona que lo ha programado, y solo inmediatamente después de escribirlo. (Después de un breve tiempo sin tocarlo, el código de un programa suele ser tan críptico para el programador como para cualquier otra cosa persona.)
Esto es un problema a la hora de enfrentarse a errores que no surjan de forma inmediata, como los errores de tipo ocasional o los derivados de cambios de versiones. Por ese motivo es esencial documentar correctamente el código: si no se entiende bien lo que está haciendo el programa en el punto en el que falla, difícilmente se podrá resolver el error sin correr un gran riesgo de estropearlo más.
Los comentarios son una herramienta fundamental para hacer el código más inteligible. Una buena táctica para hacer comentarios útiles es escribir lo que tiene que hacer el programa en lenguaje natural, antes de hacerlo en el lenguaje de programación. Hacer esto no solo sirve de ayuda a las personas que quieran leer el código más adelante, sino que también es una buena guía a la hora de escribir el programa en sí mismo.
Por ejemplo, si quisiéramos describir las operaciones de la función gauss_diasemana que se usó como ejemplo introductorio en el primer capítulo, podríamos escribir lo siguiente:
(Enero y febrero (m=1, m=2) se tratan como el año anterior
en torno a los años bisiestos)
1. Dividir el año entre centenas (c) y el resto (g)
2. Definir e y f en función del mes (de 1 a 12) y el siglo
(en ciclos de 400 años --- 4 siglos), según las tablas:
e(m) = 0, 3, 2, 5, 0, 3, 5, 1, 4, 6, 2, 4
f(siglo) = 0, 5, 3, 1
3. Seleccionar el día de la semana en función del cálculo de Gauss
x = d + e + f + g + ⌊g/4⌋
w es la división entera de x entre 7La función gauss_diasemana mostrada en el capítulo 1 está escrita usando como punto de partida ese mismo texto, convertido previamente a una serie de comentarios. El primer párrafo se ha convertido en un comentario en bloque (con los delimitadores #=, =#), y los párrafos númerados en comentarios de una sola línea (encabezados por el símbolo #). Después del primer comentario se ha añadido el bloque condicional que se describe en él, y se han eliminado las líneas que prácticamente enuncian las fórmulas reproducidas en el código, con lo que la función finalmente queda como sigue:
function gauss_diasemana(d, m, y)
#=
Enero y febrero (m=1, m=2) se tratan como el año anterior
en torno a los años bisiestos
=#
if m < 3
y = y - 1
end
# Dividir el año entre centenas (c) y el resto (g)
c = div(y, 100)
g = rem(y, 100)
# Definir e y f en función del mes (de 1 a 12) y el siglo
# (en ciclos de 400 años --- 4 siglos)
earray = [0,3,2,5,0,3,5,1,4,6,2,4]
farray = [0,5,3,1]
e = earray[m]
f = farray[mod(c,4) + 1]
# Seleccionar el día de la semana en función del cálculo de Gauss
warray = ["domingo","lunes","martes","miércoles",
"jueves","viernes","sábado"]
w = rem(d + e + f + g + div(g, 4), 7)
return(warray[w+1])
endAdemás de comentar el código, también es muy recomendable documentar las funciones mediante docstrings. Los docstrings son especialmente útiles porque no hace falta ir al código fuente para leerlos, sino que se muestran cuando se consulta la ayuda de la función. Si las funciones están bien documentadas, es mucho más fácil asegurarse de que se usan correctamente o detectar errores debidos a un mal uso de las mismas.
Tests unitarios
Para que una construcción no se desmorone es esencial que sus piezas sean robustas –además de que estén bien ensambladas–. Del mismo modo, lo primero para prevenir los fallos de un programa es asegurar que las funciones que emplea son fiables. Los llamados "tests unitarios" son pequeños programas que se escriben para poner a prueba las funciones.
Este tipo de pruebas se suelen hacer de forma espontánea mientras se están definiendo las funciones. Por ejemplo, al comienzo del capítulo 3 desarrollamos una función para crear en formato HTML el calendario de un mes cualquiera, basado en la función gauss_diasemana comentada arriba y unas cuantas más; y tras definir cada una de ellas se probaba su resultado con un ejemplo particular (el mes de agosto de 2018). Los tests unitarios no son otra cosa que una manera formal, sistemática y más exhaustiva de hacer ese tipo de comprobaciones. En lugar de hacer pruebas informales en el REPL, estas se escriben en un script que se guarda para poder repetirlas más adelante, y poder así verificar que las funciones siguen funcionando como se esperaba.
Los tests unitarios son el elemento básico de la estrategia de programación conocida como "TDD" o test-driven development (desarrollo guiado por pruebas). Se trata de un método para crear programas de forma progresiva, escribiendo primero las pruebas que han de pasar los distintos componentes de un programa, y después las funcionalidades necesarias para que las pruebas vayan pasando.
La finalidad de los scripts con los tests unitarios no es solo comprobar que las funciones se pueden ejecutar sin provocar ningún error, sino que también dan los resultados esperados. Una forma de conseguir esto es con la macro @assert.
Por ejemplo, consideremos la siguiente función, que define el resto de la división entera de una pareja de números, tomando como dividendo el más grande y como divisor el más pequeño, independientemente del orden en que se introduzcan:
function resto(a, b)
dividendo = max(a, b)
divisor = min(a, b)
return rem(dividendo, divisor)
endresto (generic function with 1 method)En principio, el resultado de esta función siempre tendría que ser más pequeño que el menor de los argumentos... pero esto solo ocurre si ambos son números positivos. Cuando se introducen números negativos esta regla ya no se cumple, y si un test incluyese esa prueba con la macro @assert, se interrumpiría con un error:
julia> a1, b1 = 5, 2;julia> a2, b2 = 5, -2;julia> @assert resto(a1, b1) < min(a1, b2) "el resto no es más pequeño que el argumento menor"ERROR: AssertionError: el resto no es más pequeño que el argumento menorjulia> @assert resto(a2, b2) < min(a2, b1) "el resto no es más pequeño que el argumento menor"
Para hacer este tipo de pruebas, después de @assert siempre ha de escribirse una expresión que dé como resultado el valor true o false. Si el resultado es true, el script continúa sin más, pero si es false se emite un error de tipo AssertionError, con el mensaje escrito como cadena de texto después de la condición. (Ese texto es opcional, de tal modo que si se omite, el mensaje de error simplemente reproduce la condición.)
Además de la macro @assert, Julia también tiene el módulo Test en la biblioteca estándar, que proporciona más utlidades para hacer tests unitarios. La principal es la macro @test, que funciona como @assert, pero no admite el texto de error personalizado, y muestra información más explícita sobre el resultado de la prueba, tanto si se pasa como si no:
julia> using Testjulia> @test resto(a1, b1) < min(a1, b2)Test Failed at REPL[2]:1 Expression: resto(a1, b1) < min(a1, b2) Evaluated: 1 < -2 ERROR: There was an error during testingjulia> @test resto(a2, b2) < min(a2, b1)Test Passed
La macro @test también facilita probar igualdades o desigualdades aproximadas con una tolerancia determinada. Por ejemplo, podemos probar la aproximación de Bhaskara I a la función seno:
julia> using LinearAlgebrajulia> sin_aprox(x) = 16x * (π - x) / (5π^2 - 4x * (π - x))sin_aprox (generic function with 1 method)julia> @test sin_aprox(π/5) ≈ sin(π/5) atol = 0.001Test Passedjulia> @test sin_aprox(π/4) ≈ sin(π/4) atol = 0.001Test Failed at REPL[4]:1 Expression: ≈(sin_aprox(π / 4), sin(π / 4), atol = 0.001) Evaluated: 0.7058823529411764 ≈ 0.7071067811865475 (atol=0.001) ERROR: There was an error during testing
Además, se pueden escribir bloques de pruebas con la macro @testset, de tal manera que los resultados de todos los tests del bloque se presentan juntos en una tabla resumen. Esto resulta especialmente práctico para repetir un mismo test sobre un conjunto de datos diversos, iterando a lo largo del conjunto de datos:
julia> @testset "Seno de Bhaskara I" begin for x = range(0, π, length=5) @test sin_aprox(x) ≈ sin(x) atol = 0.01 end endTest Summary: | Pass Total Time Seno de Bhaskara I | 5 5 0.0s Test.DefaultTestSet("Seno de Bhaskara I", Any[], 5, false, false, true, 1.759163004109612e9, 1.759163004109699e9, false, "REPL[1]")
Julia proporciona varias utilidades más, por ejemplo para verificar si una función se interrumpe con un error o emite warnings cuando corresponde, comprobar los tipos de variable que dan como resultado las funciones, etc. Estas utilidades se pueden consultar en la documentación oficial sobre el módulo Test.
El paquete Revise
Después de escribir el código de una función es necesario pasárselo a la sesión en curso de Julia para poder usarla –bien pegando el código en el REPL, leyendo el archivo que lo contiene con include, o con las herramientas que ofrecen los IDEs para ejecutar fragmentos de código–. Asimismo, si en algún momento corregimos alguna parte de la función, también tenemos que "recargarla" en la sesión de Julia, si queremos que se reconozca su nuevo comportamiento. Pero cuando se está escribiendo un programa con muchas funciones (y si se sigue el consejo que se ha dado arriba, eso debería ser lo normal), es fácil perder la pista a los cambios que se les va haciendo según encontramos fallos y los corregimos. Esto puede hacer que llegue un momento en que no sepamos si las funciones que estamos usando son las presentes en el código fuente o una versión anterior.
En esas circunstancias, una solución drástica es terminar la sesión de Julia y comenzarla de nuevo, pero eso supone tener que volver a cargar los paquetes y módulos, repetir los pasos anteriores del estudio que se estuviera haciendo, etc. Una alternativa es usar el paquete Revise. Entre otras cosas, este paquete proporciona la función includet, que hace lo mismo que include (evaluar los contenidos de un archivo de código), pero trazando los cambios que se realizan sobre él.
Esto significa que si se modifica alguna parte del archivo cargado con includet, este se "recarga" automáticamente. Las nuevas variables y funciones definidas en el código pasan a formar parte del espacio de trabajo; se aplican los cambios que se hayan hecho en sus definiciones, y en el caso de las funciones, las que se borren del código también desaparecen del espacio de trabajo.[1]
El paquete Revise solo depende de los módulos de la biblioteca estándar de Julia, por lo que se trata de uno de los pocos paquetes de terceros que se puede recomendar cargar de forma automática al inicio. Esta recomendación es especialmente aplicable para usuarios que trabajen en el desarrollo de paquetes, ya que Revise también puede seguir los cambios que se han hecho a los paquetes cargados con using o import. (Para asegurarse de que Revise funciona bien al cargarlo al inicio, conviene seguir las instrucciones mencionadas en sus páginas de documentación.)
Registro de mensajes con @debug
Hay circunstancias en las que se necesita consultar lo que ocurre en algún punto determinado de un programa sin tener que recorrer manualmente todos sus pasos, o dentro de una función cuando se ejecuta, para verificar que funciona como se espera o para entender por qué no lo hace. A continuación presentamos las herramientas principales para hacer este tipo de "investigación" o debugging.
El método más básico consiste en escribir instrucciones en los puntos de interés del programa, para registrar la información que se desea consultar. La versión más rudimentaria de este proceso sería introducir líneas de código con la función print o println para mostrar los valores de ciertas variables en ese instante, bien en la pantalla, en archivos de texto, etc.
Una opción más adecuada es usar el sistema de registro de mensajes proporcionado por Julia, que puede activarse, desactivarse y configurarse a demanda. Pongamos, por ejemplo, que queremos registrar los valores de todos los parámetros utilizados en la fórmula final de la función gauss_diasemana, es decir:
w = rem(d + e + f + g + div(g, 4), 7)Esto se puede hacer añadiendo la siguiente línea, justo después de la anterior:
@debug "Valores de la fórmula de Gauss" d e f g g_4=div(g, 4) wEn circunstancias ordinarias, esta línea no tiene ningún efecto sobre el comportamiento de la función –de hecho ni siquiera se ejecuta–:
julia> gauss_diasemana(11, 8, 2018)
"sábado"Pero si queremos se puede modificar la variable de entorno JULIA_DEBUG para que las líneas con @debug se "activen" en la sesión de trabajo presente:
julia> ENV["JULIA_DEBUG"] = Main
Main
julia> gauss_diasemana(11, 8, 2018)
┌ Debug: Valores de la fórmula de Gauss
│ d = 11
│ e = 1
│ f = 0
│ g = 18
│ g_4 = 4
│ w = 6
└ @ Main REPL[2]:22
"sábado"La variable de entorno JULIA_DEBUG identifica los módulos en los que se tendrán en cuenta las líneas con @debug. En este ejemplo se ha asignado el módulo Main, asumiendo que la función gauss_diasemana se había definido en la sesión de trabajo (directamente en el REPL o en un script cargado con include, por ejemplo). Si fuese parte de un paquete en desarrollo, en lugar de Main la función estaría definida en su propio módulo. Es posible activar el "nivel debug" de varios módulos:
julia> ENV["JULIA_DEBUG"] = Main, MiModuloO también desactivarlos todos:
julia> ENV["JULIA_DEBUG"] = ()Otra forma de activar las líneas con @debug es cambiar la configuración global del sistema de logging de Julia, con la función global_logger. Esto es especialmente útil si en lugar de presentar los mensajes emitidos (que pueden ser muchos) en la pantalla queremos dirigirlos a un archivo de texto. Por ejemplo podríamos redirigir todos los mensajes al archivo "log.txt" con las siguientes instrucciones:
io = open("log.txt", "w")
debug_logger = SimpleLogger(io, Logging.Debug)
global_logger(debug_logger);A partir de ese momento, durante la sesión de trabajo todos los mensajes de "debug" (de todos los módulos, y también los "warnings" y errores) se escribirán en "log.txt".
Para volver a la configuración original, que presenta los imágenes en pantalla e ignora los de tipo "debug", se puede cambiar el SimpleLogger por un ConsoleLogger con las opciones por defecto:[2]
close(io)
global_logger(ConsoleLogger())Hay que recordar cerrar el archivo con la instrucción close(io) para que los mensajes se queden grabados en él. Además, si se desea utilizar el mismo archivo para registrar distintos conjuntos de mensajes, hay que abrirlos con la opción "a" en lugar de "w" para que los nuevos mensajes se escriban a continuación de los anteriores, en lugar de sobreescribir el archivo.
Por otro lado, la propia función global_logger devuelve un registro con la configuración previa, que puede usarse como argumento para volver al estado anterior:
logger = global_logger(debug_logger) # cambia configuración
global_logger(logger) # vuelve a la configuración anteriorAlternativamente, si se quieren registrar solo los mensajes de un conjunto reducido de instrucciones, en lugar de configurar el registro global se puede usar un registro "temporal" con la función with_logger, del siguiente modo:
julia> with_logger(debug_logger) do
gauss_diasemana(11, 8, 2018)
end
┌ Debug: Valores de la fórmula de Gauss
│ d = 11
│ e = 1
│ f = 0
│ g = 18
│ g_4 = 4
│ w = 6
└ @ Main REPL[2]:22
"sábado"Esto hace que el registro que hemos definido como debug_logger solo se aplique a las instrucciones incluidas en el boque do ... end, sin alterar el sistema de registro global.
Infiltrator
Los registros de mensajes que acabamos de ver son como radiografías que podemos hacer a los programas y funciones para echar un vistazo a su interior. Son una herramienta sencilla y muy eficiente, pero para que resulten útiles hemos de saber dónde buscar y qué información queremos observar. Desafortunadamente muchas veces esto no es así, por lo que a menudo necesitaremos técnicas de debugging más flexibles.
Cuando tenemos localizados los puntos críticos de un programa, un método conveniente para explorarlos con más libertad es utilizar la macro @infiltrate del paquete Infiltrator, en lugar de @debug[3]. Esto hace que la ejecución del programa se detenga en ese punto. Por ejemplo, en la función gauss_diasemana podríamos cambiar las últimas líneas por las siguientes:
w = rem(d + e + f + g + div(g, 4), 7)
@infiltrate
return(warray[w+1])
endA continuación cargamos el paquete Infiltrator y empleamos la nueva versión de nuestra función:
julia> using Infiltrator
julia> include("gauss_diasemana.jl")
gauss_diasemana
julia> gauss_diasemana(11, 8, 2018)
Hit `@infiltrate` in gauss_diasemana(::Int64, ::Int64, ::Int64) at REPL[8]:22:
debug> Hay varias cosas a notar aquí:
La instrucción
using Infiltratorha de usarse antes de cargar la función que incluye la línea con@infiltrate. En este caso hemos supuesto que el archivo que contiene nuestra función se llamagauss_diasemana.jl.Al llegar a esa línea, la función detiene su ejecución, y la etiqueta del REPL cambia de
julia>adebug>, para indicar que se ha entrado en "modo de depuración" (debug mode en inglés).
En este momento se pueden ejecutar nuevas instrucciones en el REPL, que funcionarán como si estuvieran escritas en el punto de la función donde nos hemos detenido. Esto significa que podemos usar las variables locales de la función, que podemos consultar con la macro @locals:
debug> @locals
- e::Int64 = 1
- c::Int64 = 20
- earray::Array{Int64,1} = [0, 3, 2, 5, 0, 3, 5, 1, 4, 6, 2, 4]
- w::Int64 = 6
- d::Int64 = 11
- farray::Array{Int64,1} = [0, 5, 3, 1]
- g::Int64 = 18
- f::Int64 = 0
- m::Int64 = 8
- y::Int64 = 2018
- warray::Array{String,1} = ["domingo", "lunes", "martes", "miércoles", "jueves", "viernes", "sábado"]
debug> div(g, 4)
4Ahora bien, este conjunto de variables locales es cerrado. Por lo tanto, mientras se está en este modo no sirve de nada asignar el resultado de las operaciones a nuevas variables, porque estas no se crearán:
debug> g_4 = div(g, 4)
4
debug> @locals
- e::Int64 = 1
- c::Int64 = 20
- earray::Array{Int64,1} = [0, 3, 2, 5, 0, 3, 5, 1, 4, 6, 2, 4]
- w::Int64 = 6
- d::Int64 = 11
- farray::Array{Int64,1} = [0, 5, 3, 1]
- g::Int64 = 18
- f::Int64 = 0
- m::Int64 = 8
- y::Int64 = 2018
- warray::Array{String,1} = ["domingo", "lunes", "martes", "miércoles", "jueves", "viernes", "sábado"]
debug> g_4
ERROR: UndefVarError: g_4 not definedLo que sí se puede hacer es crear una nueva variable global (p.ej. global g_4 = div(g, 4)), que se mantendrá en Main cuando se salga de la función. (Véanse más detalles en la sección sobre Variables globales y locales en el capítulo 8.)
Para salir del modo debug basta con pulsar Ctrl+D.
Hay dos maneras de desactivar y reactivar el efecto de @infiltrate sin redefinir la función:
Si se ejecuta la macro
@stopdentro del modo debug, el punto de interrupción (breakpoint) actual dejará de tener efecto la siguiente vez que se ejecute el programa o la función. La instrucciónInfiltrator.clear_stop()reactiva todos los breakpoints.Se puede añadir una condición después de
@infiltrate, de tal modo que el breakpoint se active solo cuando esa condición es cierta. Por ejemplo, se podría crear la variableMain.activar_infiltrate[4] que podamos definir arbitrariamente comotrueofalse, y en la línea en la que queremos detener el código escribir:
@infiltrate Main.activar_infiltrateAunque la macro @infiltrate nos proporciona una posibilidad de interacción que no tiene @debug, una desventaja frente a la macro más simple es que depende de un paquete externo. Así, si en un programa dejamos una línea con @debug, este se podría ejecutar sin problemas cuando no estemos depurándolo; pero si dejamos la macro @infiltrate en el código, en una sesión de Julia posterior el programa fallaría si no se carga el paquete Infiltrator con antelación. Así que cuando se use esta herramienta, es importante acordarse de borrar las líneas con @infiltrate cuando se haya acabado de hacer la depuración.
Tener el paquete Revise en funcionameinto hace más fácil usar Infiltrator: en los scripts que se hayan cargado con includet, también se pueden activar y desactivar breakpoints simplemente escribiendo y borrando las líneas con @infiltrate, respectivamente.
Debuggers dinámicos
Cuando queremos investigar el funcionamiento de un programa, pero los puntos críticos no están bien definidos desde un principio o pueden ir cambiando de un caso a otro, lo que necesitamos es un debugger dinámico, que ofrece mayor flexibilidad para detener la función en distintos lugares, en lugar de puntos fijos como hemos visto con las herramientas anteriores.
El paquete Debugger permite depurar un programa de este modo a través del REPL.[5] Si se ejecuta una expresión precedida de la macro @enter, su ejecución se detendrá en la primera lína de código, en un modo debug muy semejante al que se ha visto con Infiltrator, pero con dos diferencias importantes:
- Además de hacer operaciones en ese mismo punto del código, se pueden ejecutar instrucciones para detenerse en la siguiente línea, dentro de funciones a las que se llama, etc. (véanse los detalles en la página web del paquete).
- Esta mayor libertad tiene un precio: para poder detener el programa de forma arbitraria en cualquier punto del código hay que renunciar a compilarlo, lo que en general hará que funcione más lento; a veces mucho más lento.
También es posible hacer avanzar el programa y detenerse en un punto arbitrario, añadiendo breakpoints. Pero en este caso disponemos de múltiples formas de definir los breakpoints:
- Añadiendo al código la macro
@bpen la línea correspondiente. Como ocurre con Infiltrator, esta forma de añadir breakpoints hace que el programa solo se pueda usar si se tiene cargado el paquete Debugger. - La función
breakpoint(f, n)añade un breakpoint en el archivo de código o la función con el nombref, en la línean. Ese breakpoint no altera el código original, y solo está disponible en la sesión presente. Si el breakpoint se asigna a una variable (b = breakpoint(...)), este se puede activar, desactivar o borrar con operaciones comoactivate(b),enable(b)odisable(b). - La macro
@breakpoint f(x) ntambién sirve para fijar un breakpoint en la línean; si se trata de una función con distintos métodos definidos, el breakpoint se añade en el que se ejecutaría con el argumentox.
Para que el programa se detenga en esos breakpoints es necesario que se ejecute en "modo debug". Para ello, el script o la función en cuestión ha de ejecutarse precedida de @enter, o bien con @run para que no se detenga en la primera línea, sino directamente en la marcada con el breakpoint.
Debugger en VS Code
Hay IDEs que también proporcionan un debugger con herramientas gráficas. En particular, la extensión para Julia de VS Code permite usar las macros @enter y @run para entrar en "modo debug" sin instalar el paquete Debugger. Con esa herramienta el control de la ejecución resulta más visual: las operaciones como ir a la siguiente línea, saltar al siguiente breakpoint, entrar o salir de la función, etc. se pueden manejar desde un conjunto de botones (véase la barra superior en la Figura 1); los breakpoints se marcan como botones rojos sobre el archivo de código, pulsando junto al número de línea correspondiente (como en la línea 18 del ejemplo de la figura), etc.
Por otro lado, cuando se entra en modo debug en VS Code se cambia de entorno visual. Durante las interrupciones el REPL integrado en VS Code no está operativo, y las instrucciones a ejecutar se introducen en el "debug console". Además, la interfaz del debugger tiene su propio explorador de variables que es distinto del habitual, más otros menús, cuyo funcionamiento está explicado en la documentación de la extensión de VS Code.
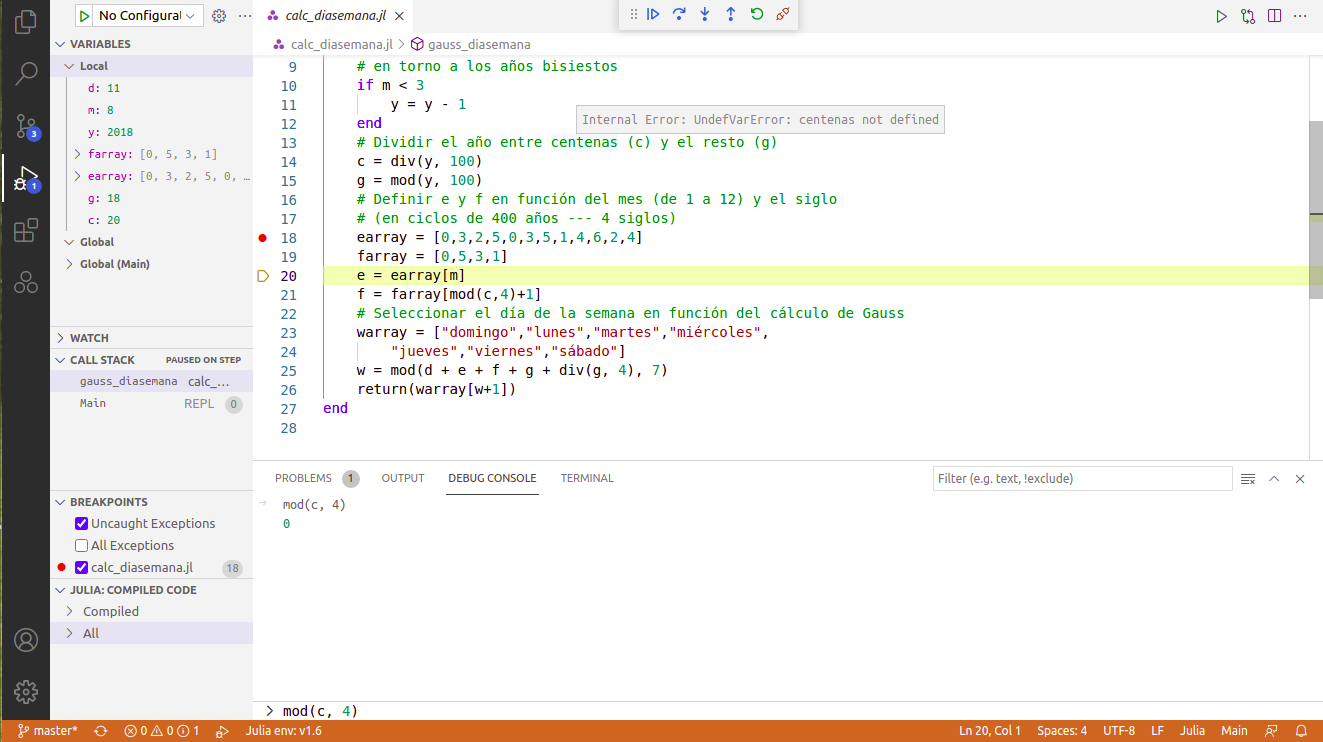
Figura 1. Entorno de debugging en VS Code
Debug en modo compilado
Como se ha señalado arriba, un inconvienente notable de ejecutar un programa en "modo debug" es que en general es mucho más lento, tanto más lento cuanto más complejo es el programa. Una forma de reducir ese problema es ejecutar las operaciones que no interese inspeccionar en "modo compilado". El paquete Debugger permite activar el modo compilado forma interactiva, y la extensión de Julia para VS Code utiliza una lista de funciones y módulos cuyas funciones se ejecutan de ese modo durante los procesos de debugging (véase el menú "compiled code" abajo a la izquierda en la figura 1).[6] Las funciones ejecutadas en modo compilado correrán a la velocidad de costumbre. Ahora bien, los breakpoints marcados en el código de las mismas no son operativos.
Consideremos, por ejemplo, que se ha entrado en modo debug en un programa con las siguientes líneas:
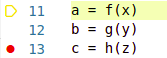
A modo de ayuda visual, el código se muestra como se vería en el editor de VS Code. La primera línea (#11) está resaltada, indicando que la ejecución se ha detenido en ese punto. El punto rojo en la tercera línea señala un breakpoint. Supongamos, además, que dentro del código de la función g (que no se muestra aquí) también se ha activado otro breakpoint.
Si se selecciona la opción de "continuar" la ejecución, normalmente la siguiente interrupción tendría lugar durante la ejecución de la segunda línea, en el breakpoint que hay dentro de la función g. Pero si la función g se encontrara en la lista de funciones compiladas, la función g se ejecutaría sin detenerse, y la interrupción se daría en el breakpoint de la tercera línea, que está al mismo "nivel" que el punto desde el que se reanuda la ejecución.
Por defecto la lista de funciones compiladas incluye solo las de Base y los módulos estándar. Eso permite acelerar muchas de las operaciones que se realizan en cualquier programa sin riesgo de saltarse breakpoints (que normalmente suelen añadirse al código propio). Pero en cualquier momento pueden añadirse funciones propias o de otros paquetes, que sean complejas y lentas de ejecutar en modo debug, y que no interese inspeccionar.
Sumario del capítulo
En este último capítulo hemos visto diversas estrategias y herramientas para afrontar los errores de programación, reduciendo el riesgo de que ocurran, y detectarlos y analizarlos de forma eficaz cuando no se han podido evitar. Lo más eficaz es adoptar unos buenos hábitos de programación, documentando adecuadamente y probando de forma continua las pequeñas piezas que conforman un programa. Pero además Julia ofrece una serie de ayudas, sobre todo a través de paquetes, que facilitan esa tarea, y entre ellas hemos explorado, en particular:
- Las herramientas para hacer tests unitarios, mediante la macro
@asserto las utilidades del módulo estándarTest(las macros@test,@testset, entre otras). - El registro de mensajes con la macro
@debug, que se pueden mostrar en pantalla o volcar a archivos para analizarlos posteriormente. - El uso del paquete Revise para facilitar la continuidad del trabajo a la vez que se redefinen funciones, módulos y otros elementos.
- El uso de paquetes como Infiltrator o Debugger, y herramientas análogas de algunos IDEs, para detener la ejecución de programas en puntos de interés.
- 1Usando el paquete Revise también se pueden redefinir módulos de manera segura sin reiniciar la sesión de trabajo. Lo que no se pueden actualizar son las definiciones de tipos de variables. La definición de módulos y de tipos son aspectos algo más avanzados, que no se abordan en esta guía.
- 2La differencia entre un
ConsoleLoggery unSimpleLoggeres que el primero da formato al texto para presentarlo en pantalla de forma más legible. Para ambos tipos el primer argumento es el archivo en el que se van a registrar los mensajes (stderrpor defecto), y el segundo es el nivel de prioridad. Hay cuatro niveles de prioridad, que en orden ascendente son:Logging.Debug(el de menor prioridad, pensado para desarrolladores y que es el que se ha puesto en el ejemplo),Logging.Info(información dirigida al usuario),Logging.Warning(avisos de que puede pasar algo anormal) yLogging.Error(mensajes de fallos críticos, que normalmente harán que se interrumpa la ejecución del código). Por defecto se muestran los mensajes de nivelInfoo superiores. Este sistema se describe con detalle en la sección Logging del manual oficial. - 3La versión de Infiltrator usada para estos ejemplos es la v0.3.
- 4El motivo por el que se sugiere definir explícitamente esta variable en el entorno global de
Maines para asegurar que es esa la variable que controla el comportamiento de@infiltrate, en el caso de que hubiera alguna variable local con el mismo nombre en el entorno de la función manipulada. - 5La versión de Debugger considerada en este texto la v0.6.
- 6El menú "compiled code" mostrado aquí se corresponde con la versión 1.2 de la extensión de Julia para VS Code.